Implementation Details
1. XRender
Overview:
XRender
itself is not very well documented, so I'll give here a short overview
about its concepts.
A more detailed documentation
is the protocol specification, which is, however, not always accurat.
The
most recent version I was able to find is located here.
- Introduced 2001 with XFree86-4.0.1 as X11 Extension
- Designed to fix limitations of X11 “core drawing”
- Very flexible API, ~99% of Java2D's functionality without ugly workarrounds
- (Almost) not documented
- Hard to guess which features are accelerated, many corner-cases
- Only rarely used in a direct way, only through Cairo or QT4
- Chicken/Egg problem (no one uses it because its slow, no one tuned it because its not used)
- Sometimes hard to accelerate with fixed-function GPUs
1.1 XRender compared to the
X11 drawing model:
Instead
of XLib's GCs, XRender works with „Pictures".
A Picture is
quite equal to a GC or a Graphics2D object in Java, it stores the
surface state - and one surface can have mutiple pictures assoziated
with it, each holding its own state information.
However some
states account only when used as
source, some only when used as destination and some for both.
Support
for A8, RGB24 and ARGB32 surfaces is guaranteed by the Render
specification and furthermore
XRender now allows composition of pictures with different depths.
1.2 Composition:
The
central functionality of XRender is Composition with mask or without,
which maps
quite well with Java2Ds concept of paints.
Geometry is drawn
into a mask which then is used for the composite operation.
The
only two geometry types XRender provides are Trapezoids and Rectangles,
however trapezoids are not accalerated by any driver for now.
Its limited geometry support is a real weakness of XRender.
Also text-rendering is
interpreted as some kind of composition.
The glyphs are first blited to
a temporary mask, following a composition with that mask:
Transformation
can be applied to source and mask-pictures.
2. Pipeline design overview:
2.1 The "old" XRender pipeline:
The "old"
XRender Java2D pipeline was a "traditional" pipeline which followed the
design of the X11 pipeline.
Communication with the native code is done
over JNI, and a lot of logic was scattered between Java and C code, sometimes in a redundant way.
This approach was hard to maintain, furthermore JNI-overhead showed up for small primitives.
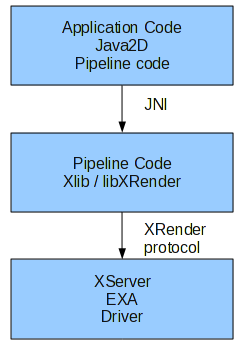
Design of the "old" XRender pipeline
2.2 The rewritten Pipeline:
The
goal of the rewrite was to reduce the JNI overhead as far as possible
and to ease maintenance as well as further improvements.
This is archieved by generating the X11/XRender protocol directly with Java-Code, and using XCB's socket handoff functionality.
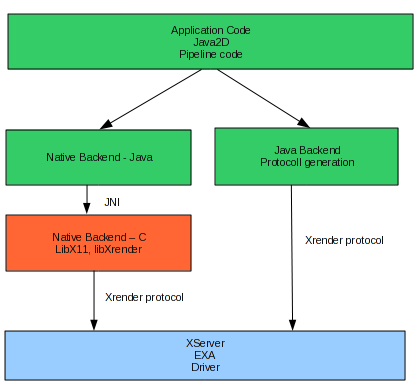 Java code
Native C code
XServer process
Java code
Native C code
XServer process
XCB is a low-level replacement for libX11, which also offers a libX11 compatibility library.
XCB's socket handoff functionality allows to send self-generated X11 protocol to the XServer.
It allows sharing the socket with native code, which is important
considering the whole AWT code is still based on the native
libX11/libxcb.
Unfourtunatly XCB's socket handoff functionality isn't stable and causes frequent deadlocks inside XCB code.
This led to the development of two different backends:
- Pure Java backend
The pure Java backend generates X11 protocoll directly in Java-code and
flushes the data to the native socket when either the buffer is full or
a native library requests access to XCB.
All code executed is Java and can be highly optimized and inlined by the Java Runtime.
- Native backend:
- Compatibility solution until XCB bugs are fixed
- Works on systems without (or old) XCB based libX11
- Lower performance, one JNI call per X-request (even more JNI overhead than "old" pipeline)
3. Java2D -> XRender mapping:
3.1 Aliased rendering:
Java2D transforms complex shapes into many
zero-width lines and
rectangles, therefor processing those lines and rectangles fast is
critical for archieving high performance.
An early prototype
composited rectangle-by-rectangle without using a mask but it turned
out that composition for small areas has a too high setup costs.
The
current design buffers all rects and lines, then draws them
in one go to the mask-picture (instead of drawing scanline-by-scanline
like the old pipeline did) and uses that mask for composition.
There
are several optimizations implemented, like drawing rectangles directly
to destination when a solid color is used as source.

Filled shape, rendered with 1px high rectangles (scanlines)
Different colors used for better illustration
XRender does not support zero-width lines, the only possibility to
draw that often used primitive is to emulate it with Trapezoids, with a
lot of complex geometric calculations going on to guarantee the line is
really a zero-with-line (Hobby Pen Polygon).
The XRender pipeline works arround that issue by drawing diagonal lines to a Mask using a X11-GC.
EXA
itself does not accalerate diagonal lines, so rendering the lines to
the same mask as the rectangles does cause excessive migration.
The
solution choosen was to draw diagonal lines to a seperate mask which is
never marked to have a modified VRAM "copy", therefor only
sysram->vram migration happens which is relativly fast.
UXA faces the same problem, however it doesn't provide a workarround,
therefor all lines are converted to rectangles using a Bresenham's line
rendering algorythm.
3.2 Antialiased Rendering:
Antialiasing
is currently done in the same way as by the D3D/OGL pipeline:
Mask
tiles are generated in software, uploaded to the GPU and composition is
accalerated finally.
Although composition is now accalerated, direct
image access using shm pixmaps is not possible when running on EXA,
which means the mask-tiles have to be transported over the X11 network
protocol which currently only results in performance compareble to the X11
pipeline running on XAA. However when running on EXA or over network
performance is a lot better compared to the X11 pipeline.
For the
pipeline there is almost no difference between MaskFills and MaskBlits,
solid MaskFills simply use a 1x1 repeating picture to store the
color-value.
Further optimizations could include tile-buffering
for large AA'ed shapes or buffering the AA tiles in the MaskBuffer,
avoiding many small composition operations.
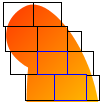
Antiliased shape with Gradient source.
Composition with <= 32x32 tiles, covereage calculated by CPU.
No RAM->VRAM copy for fully covered tiles (blue).
3.3 Text Rendering:
XRender
has a very flexible text API.
Glyphs are uploaded to the XServer, and later referenced by a unique ID.
Basic Layout-Information is stored
per-glyph (XGlyphInfo), however its possible to influence positioning
in a relative manner using the XGlyphElt structures at rendering time.
The correction done by XGlyphElt does not overwrite the positioning
information stored in XGlyphInfo, but is added to.
All text antialiasing modes are supported and accalerated.

Different antialising modes supported.
3.4 Paint support:
Java2D supports the following paint-modes:
- Solid Colors
- Texture
- Gradients
- XOR
All paint-modes except XOR can be combined with Alpha blending.
Solid:
For a solid colors a 1x1 pixmap is first filled with the color and later used as source-picture in the composition step.
If no blending is required, the backend reduces this operation to a direct XRenderFillRectangle call.
Texture:
For TexturePaints a texture-picture is used as source:
Gradient:
Linear- and radial gradients are supported, with the exception of radial gradients where focus-point != center point.
Currently no XRender capable driver is able to accalerate gradients,
therefor gradients cause software-fallbacks on the server-side.
In
EXA the gradient "surface" is pinned to sysram, causing all other
surfaces which are involved in the composition migrated back to sysram
which is an relativly expensive operation.
The XRender pipeline is
able to pre-generate a gradient to a surface never marked to have
a modified VRAM "copy", which improves gradient performance on current
EXA/driver combinations a lot.
However when gradients are accalerated, this would be unescessary overhead, so this workarround can be disabled:
-Dsun.java2d.gradcache=false
Bitwise XOR (as expected by Java2D) is only supported by X11 core drawing, XRender only supports XOR specified by Porter-Duff.
XOR was introduced with Java-1.0, and is often used by legacy software to paint selected areas to save repaints.
The fact that the highest-rated bug for the new Direct3D pipeline was
about XOR performance problems, seems to indicate still a lot of
software is in use depending in this feature.
To avoid slow fallbacks, especially in the remote case, the pipline uses an X11-GC for aliased fills (lines, rectangles).

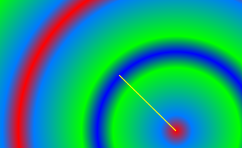
Texture & Radial Gradient Paint
3.5 Image/Blit support:
The XRender pipeline accalerates all various blit operations supported by Java2D, including:
- Linear & Billinear interpolation
- Transformation
- Optimized image upload for images which can not be cached (so called Software-to-Surface Blits)
Billinear interpolation is a bit tricky, because XRender interpolates
with the border-value by default - whereas Java2D specifies the image
border as not interpolated. This was solved by setting the repeat-mode
to RepeatPad (similar to GL_CLAMP in OpenGL) and by using a transformed
mask with a rectangle rendered into it.
By adjusting the transformation of the mask, its often possible to save
a lot of fillrate (by e.g. using a scale transformation).
This way additional overhead can be reduced to a minimum.

4x4 image with transformation applied
1. Java2D, 2. XRender
|
Image with non-interpolated border
|

